Memory Post-Processing
📊 Process Overview
-
Post-processing request initiated
-
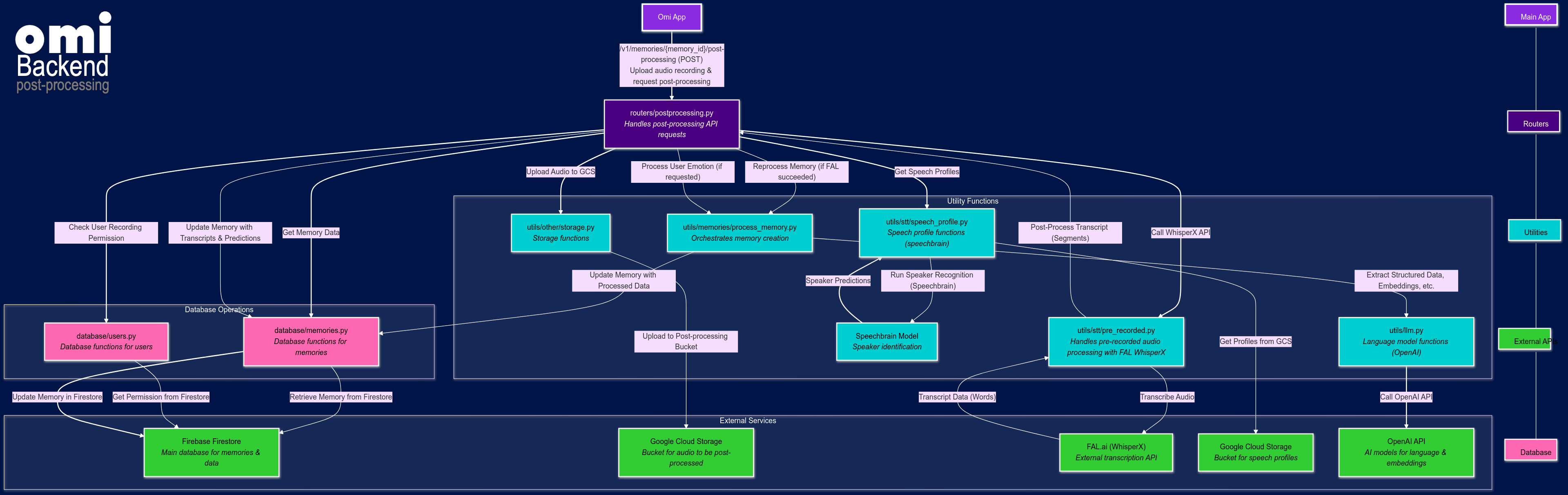
Request handled by
routers/postprocessing.py -
Audio pre-processed and stored
-
FAL.ai WhisperX transcription performed
-
Transcript post-processed
-
Speech profile matching for speaker identification
-
Memory updated and reprocessed
-
Optional emotional analysis
🔍 Detailed Steps
1. Post-Processing Request
- Omi App sends POST request to
/v1/memories/{memory_id}/post-processing - Request includes:
- Audio recording for post-processing
- Flag for emotional analysis
2. Request Handling
postprocess_memoryfunction inrouters/postprocessing.pyprocesses the request- Retrieves existing memory data from Firebase Firestore using
database/memories.py
3. Pre-Processing and Storage
User Permission Check
- Checks if user allows audio storage (
database/users.py) - If permitted, audio uploaded to
memories_recordings_bucketin Google Cloud Storage
Audio Upload for Processing
- Audio uploaded to
postprocessing_audio_bucketin Google Cloud Storage - Handled by
utils/other/storage.py
Cleanup
- Background thread started to delete uploaded audio after set time (e.g., 5 minutes)
4. FAL.ai WhisperX Transcription
fal_whisperxfunction inutils/stt/pre_recorded.pysends audio to FAL.ai- WhisperX model performs high-quality transcription and speaker diarization
- Returns list of transcribed words with speaker labels
5. Transcript Post-Processing
fal_postprocessing function in utils/stt/pre_recorded.py:
- Cleans transcript data
- Groups words into segments based on speaker and timing
- Converts segments to
TranscriptSegmentobjects
6. Speech Profile Matching
get_speech_profile_matching_predictions in utils/stt/speech_profile.py:
- Downloads user's speech profile and known people profiles
- Uses Speechbrain model to compare speaker embeddings
- Updates segments with
is_userandperson_idflags
7. Memory Update and Reprocessing
- Memory object updated with improved transcript and speaker identification
- Updated data saved to Firebase Firestore
- If FAL.ai transcription successful:
process_memoryinutils/memories/process_memory.pyre-processes memory- Re-extracts structured data (title, overview, etc.)
- Re-generates embeddings
- Updates memory in vector database
8. Emotional Analysis (Optional)
If requested:
process_user_emotionfunction called asynchronously- Uses Hume API to analyze user's emotions in the recording
- Can trigger notifications based on detected emotions
💻 Key Code Components
# In routers/postprocessing.py
@router.post("/v1/memories/{memory_id}/post-processing", response_model=Memory)
def postprocess_memory(memory_id: str, file: UploadFile, emotional_feedback: bool = False):
# ... (request handling and pre-processing)
words = fal_whisperx(audio_url)
segments = fal_postprocessing(words)
segments = get_speech_profile_matching_predictions(uid, segments)
# ... (memory update and reprocessing)
if emotional_feedback:
asyncio.create_task(process_user_emotion(uid, file_path))
# In utils/stt/pre_recorded.py
def fal_whisperx(audio_url: str):
# ... (FAL.ai API call and processing)
def fal_postprocessing(words: List[dict]) -> List[TranscriptSegment]:
# ... (clean and format transcript data)
# In utils/stt/speech_profile.py
def get_speech_profile_matching_predictions(uid: str, segments: List[TranscriptSegment]):
# ... (speaker identification logic)